Deploying SQL server Always on Availability Group on Azure Kubernetes Services(AKS).
In this blog, we will learn how to deploy the SQL server Always on Availability group on Azure Kubernetes Services.
In this blog, we will learn how to deploy the SQL server Always on Availability group on Azure Kubernetes Services.
In this blog, we will learn how to deploy the SQL server container on Azure Kubernetes services with High availability. We will use the persistent storage feature of Kubernetes to add resiliency to the solution. In this scenario, if the SQL server instance fails, Kubernetes will automatically re-create it in a new POD and attach it to the persistent volume. It will also provide protection from Node failure by recreating it again. If you are new to Kubernetes we will start by understanding the basic terminology of Kubernetes and its Architecture.
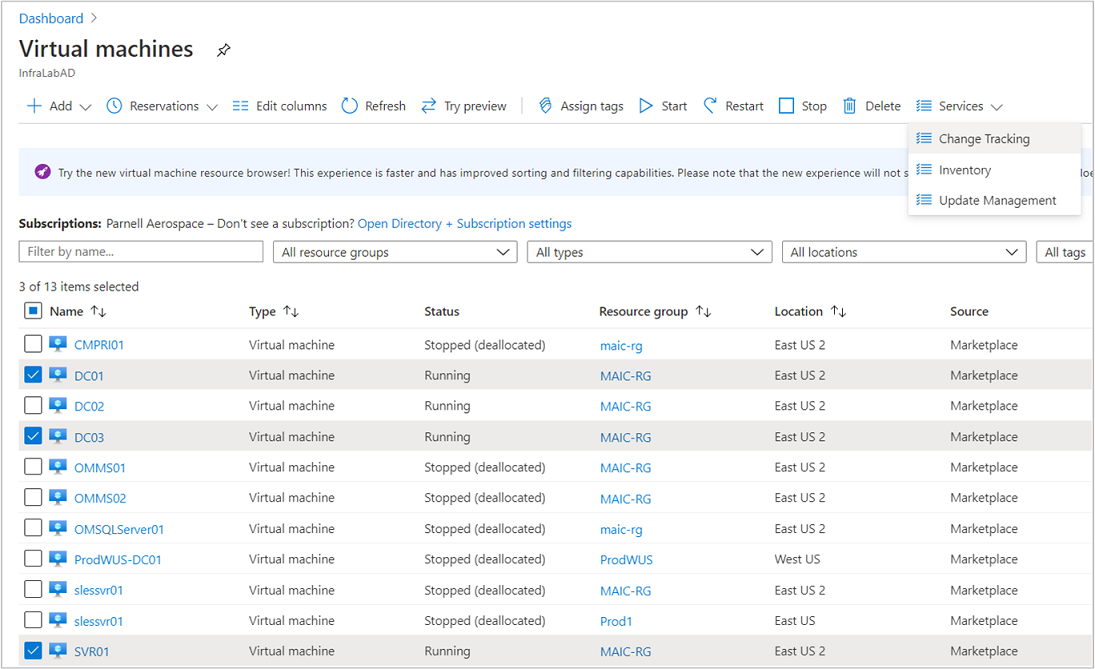
Suppose you built a large environment in Azure with more than 1000 Virtual machines. Now we need to provide the Virtual Machine details to the customer(or raise the SNOW ticket) and it is very difficult to collect each VM detail manually from Azure Portal. Also, there can be another use case if you want to verify the VMs to compare with each other to ensure all the VMs are created the same way. For example, the Cache setting for all the VMs should be Read /Write. You may also want to grab details of all the data disks and OS disks and their size, name info, and cache settings. This script grabs all the info in one shot and exports it into a CSV file for further manipulation.Let’s dive in.
The default installation of databricks creates its own Virtual network and you do not have any control over it. But If you want to deploy Databricks into your own private network due to security reasons. So this blog is for you. We will learn how to deploy Databricks into its own Private VNet. Let’s dive in.
In this blog we will learn about Azure container services and how to deploy SQL server 2019 on Azure Container Services.
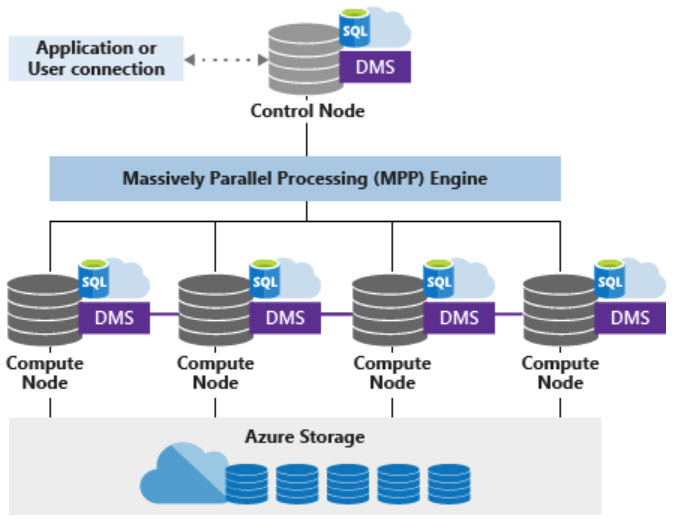
Azure Synapse (Azure SQL Data Warehouse) is a massively parallel processing (MPP) database system. The data within each synapse instance is spread across 60 underlying databases. These 60 databases are referred to as “distributions”. As the data is distributed, there is a need to organize the data in a way that makes querying faster and more efficient.In this blog we will learn how to choose the right distribution strategy.
In this blog, we will discuss a real-time scenario of deploying software on multiple Linux and Windows Virtual machines simultaneously. Suppose you have 500 virtual machines both Windows and Linux and you want to push the software to these virtual machines. Obviously, it is not a workable solution to perform the manual installation on these 500 VMs. But there is good news that Azure provides a custom script extension for remote command execution. Let’s learn how to use it?
In this blog, I will share the script to retrieve the Azure resources inside the Azure subscription. This script iterates through each resource group inside an Azure subscription and retrieves each resource name resource type and resource tag and dumps the information inside a CSV file. So let’s dive in.
This blog discusses the step by step approach to mount the storage account to Azure Databricks.
In this blog post, we will learn about VNet Peering, Hub, and spoke Architecture and Service chaining in Azure.